
Every guide about data collection methods starts with the same list. Survey, interview, observation, questionnaire. Maybe 6 items, maybe 10. Short definition for each, a note that "the right choice depends on your goals," and you're done.
That list isn't wrong. It's just the wrong starting point.
The teams that build data collection systems they actually use don't start by picking a method. They start by asking what decision the data needs to drive — and only then do they figure out what to collect and how. The teams that start with the method end up with pipelines feeding data nobody queries, storage bills that grow every quarter, and engineers who can't tell you why they're collecting half of what they're collecting.
This guide covers the full picture: what data collection actually is, how the classic methods work, how AI is changing the field in 2026, and a practical framework for making the decision in the right order.
What is data collection?
Data collection is the process of gathering, measuring, and organizing information to answer a specific question or support a specific decision. That's it. The validated techniques, the research frameworks, the five-stage process — those are all tools in service of that one goal.
The problem is that in software products, the goal gets lost. Teams inherit collection patterns from previous engineers, add new tracking for every new feature, and never remove anything. Within 18 months, the system is collecting everything and using almost none of it.
There are two distinct contexts where data collection happens, and most guides conflate them:
Research data collection is structured, time-bound, and purpose-built for a specific study or report. You design it, run it, analyze it, and move on. Academic methodology, survey design, sampling theory — all of this is built for this context.
Product data collection is continuous, operational, and embedded in your software. It runs 24/7, it scales with your user base, it feeds decisions in real time. The signals it collects either drive better product decisions or quietly accumulate as waste.
The methods overlap, but the architecture decisions don't. This guide covers both, but most of what you need for building software is in the second category.
The two types of data you'll collect
Before choosing any method, you need to know what kind of data you're after.
Qualitative data is descriptive. It captures opinions, reasoning, feelings, and context. It answers "why" rather than "how many." Interviews, open-ended survey responses, user session recordings, and focus group transcripts are all qualitative. This data is harder to measure and harder to scale, but it's the only type that tells you what's actually happening in a user's head.

Quantitative data is numeric. It captures counts, rates, durations, percentages. It answers "how many," "how often," and "how much." Event logs, click counts, completion rates, session lengths — all quantitative. This data is easy to aggregate and analyze at scale, but it tells you what users do, not why they do it.
The choice between them isn't a matter of preference. It's a matter of what question you're trying to answer. If you're trying to understand why users abandon checkout, qualitative methods tell you. If you're trying to know what percentage of users abandon at which step, quantitative methods tell you. For most product decisions, you need both.
The problem with starting at the method
Here's the pattern we see constantly.
A team wants to "collect user data." They pick behavioral tracking because it seems comprehensive. They instrument everything — every click, every scroll, every hover. Data starts flowing. They build a dashboard. Six months later, nobody opens the dashboard because it shows activity metrics that don't map to any actual decision the product team makes.
Or: a team builds a B2B SaaS product and sets up a Stripe webhook to capture payment events. Fine. But they also start logging every API call, every session token refresh, every background job. The database grows. Costs grow. Security exposure grows. Nobody ever queried 80% of that data.
This is the "collect everything" default, and it's embedded in how the cloud works. Storage is cheap per gigabyte. The cost of keeping everything feels small. But it compounds.
Every byte of data held in active infrastructure requires energy to store, process, and back up. Data you don't use adds to your cloud costs, your attack surface, and your compliance burden. Under GDPR and CCPA, data you hold is data you're responsible for — and regulators in 2026 have ended the grace period for vague data retention policies.
The root cause isn't negligence. It's starting with the method before knowing what the data is supposed to do.
The Intent-First Collection Model

There's a better sequence. Four steps, in order:
- Define the decision — What operational, product, or ML decision will this data enable?
- Map the required signal — What specific change in state or event indicates something decision-relevant happened?
- Match the collection method — Now choose the method that captures that signal reliably, at the right frequency, at acceptable cost.
- Design for sustainability — Before you build anything, define what happens to this data after 30 days, 1 year, 5 years.
This is the Intent-First Collection Model. Most data collection failures trace back to skipping step 1 or step 4 — or doing step 3 before steps 1 and 2.
Step 1: define the decision
The only question that matters at this stage: what will someone do differently based on this data?
If the answer is "we'll analyze it at some point," that's not a decision. Don't collect yet.
Decision types in software products break into four categories:
- Operational decisions — What action should a person or system take right now? (Which route maximizes revenue per collection run? Is this pig showing early signs of illness?)
- Product decisions — What should we build or change next? (Are users completing onboarding? Where are they dropping off?)
- ML training signals — What patterns should the model learn? (What does a high-quality sales practice session look like?)
- Reporting and compliance — What do stakeholders need to see? What do regulators require you to track?
Each type has different freshness requirements, different volume needs, and different retention implications. Getting this right before you write a single collection endpoint saves weeks of work later.
When we built Revenue Boosters — a route management SaaS for an amusement operator managing coin-operated machines across hundreds of locations — the decision was specific: which route produces the most revenue per hour of collector time? That one question defined everything that followed: what to collect, when, how often, and how long to keep it.
Step 2: map the required signal
A signal is not a table or a database field. A signal is the specific event or state change that indicates something decision-relevant happened.
Mapping to your signal forces the specificity that most collection designs skip. "User behavior" is not a signal. "User completed onboarding step 3 and then did not return within 48 hours" is a signal. The first is a category. The second is something you can act on.
Signal types:
- Event signals — Something happened: a user clicked, a machine was serviced, a payment was processed
- State signals — Something is true right now: a device is offline, a subscription is active, a pig's weight is outside normal range
- Aggregate signals — A pattern over time: average session length declining, completion rate below threshold
- Delta signals — Change from a previous state: response time increased 40% since last deploy
For HeyPractice — an AI-powered sales training platform — the decision was "what should this learner practice next?" That decision required a specific signal: not whether the session was completed (too coarse), but a per-session performance score across multiple competency dimensions. The signal design came first. The collection method followed from it.
Step 3: match the collection method
Now the list makes sense. Here are the main methods, organized by what signal type they're actually built to capture.
Surveys and questionnaires
Best for: explicit preference signals, satisfaction states, opinions that users won't express through behavior alone.
Surveys ask users directly. That's their strength and their limit. They're fast to deploy and cost-effective at scale, but self-reported data carries bias — people describe what they think they do, not always what they actually do.
Use surveys when the signal you need can only come from the user's own perspective: satisfaction ratings, feature prioritization input, pricing sensitivity. Don't use them as a substitute for behavioral data when behavioral data is available and more reliable.
Interviews and focus groups
Best for: hypothesis formation, understanding the "why" behind behavioral data, exploring problems you haven't fully defined yet.
Interviews are qualitative. They scale poorly — you can run 10 good user interviews in a week, not 10,000. But for understanding what's really driving a behavior pattern, a well-run interview series is faster than trying to instrument your way to the same insight.
Focus groups are useful for exploring reactions to new concepts or contested design decisions. The risk is groupthink: participants influence each other's answers. A two-moderator format — where one challenges the room and one records — reduces this.
In product development, interviews belong at the start of a new feature cycle, not as an ongoing collection method. They're expensive per data point, and their value is in generating questions, not confirming answers.
Behavioral observation and passive tracking
Best for: continuous event signals in digital products — what users actually do, not what they report.
This is the most important method for software product teams and the one most underspecified in traditional data collection guides. Passive tracking captures user actions in your product automatically: page views, clicks, session length, feature usage, drop-off points.
Modern behavioral collection tools (Mixpanel, Amplitude, PostHog) let you instrument events without writing custom logging for each one. The risk is over-instrumentation — tracking every possible event because it's easy, then drowning in data that doesn't map to any decision.
The Intent-First sequence applies here most directly. Before you add a tracking event, ask: what decision does this event signal inform? If you can't name the decision, don't add the event.
API-based and automated collection
Best for: high-frequency event signals, system state, operational data that needs to flow between systems in real time.
In 2026, API-based collection is the standard for any SaaS product that integrates with other software. Webhooks push events the moment they happen. Change Data Capture (CDC) streams database-level changes to downstream systems without polling. GraphQL APIs let consuming systems request exactly the data shape they need.
For EveryPig — a first-of-its-kind pig health and welfare platform — there was no commercial collection tool that captured the right signals for production decisions. The platform needed continuous health data from farms, fed into AI/ML models that detect early warning signs. That required a custom collection layer: sensor inputs, manual farm observations, and supply chain events, all flowing into a unified data model. Off-the-shelf tools weren't built for it. The signal requirements defined the architecture.
Forms and structured field input
Best for: operational contexts where a human records a specific state or event — field service, healthcare, logistics, compliance.
This is the physical-world equivalent of passive tracking. A field technician completing a service inspection, a nurse recording a patient observation, a collector logging machine revenue on a mobile app — all of these are structured field collection events.
The design challenge is friction reduction. The more fields in a form, the more errors and skipped entries you get. Intent-first design of field forms asks: what's the minimum data required to support the downstream decision? Everything beyond that is burden.
Secondary data and existing sources
Best for: benchmarking, context, and hypothesis testing — especially before you build a primary collection system.
Secondary data is data someone else already collected: industry reports, government statistics, academic datasets, competitor public data. It's cheap and fast to access, but you don't control the methodology, and it may not match your exact use case.
In product development, secondary data is most useful for validating that a problem is real before you invest in a primary collection system to measure it.
How AI is changing data collection in 2026
The methods above have existed for decades. What's changed is how they're executed, what's now possible, and where the new risks are.
Automated data extraction. AI-powered OCR and document processing tools can now extract structured data from invoices, contracts, forms, and emails without manual entry. What used to require a data entry team now runs automatically with AI validation flagging exceptions for human review. The practical impact: operational data collection pipelines that previously cost $10-20 per hour of human time now run at near-zero marginal cost.
Synthetic data generation. When you're training an ML model and you don't have enough labeled examples, LLMs can generate synthetic training data. The math on this is counterintuitive: 500-2,000 carefully curated synthetic examples after filtering typically outperform 50,000 raw generated examples. Quality beats quantity in training data, and AI makes it economical to generate high-quality examples rather than hoarding every raw data point.
This changes how teams should think about data retention. "Keep everything for future model training" used to be defensible. In 2026, you can generate task-relevant examples when you need them. You don't need to store raw behavioral data indefinitely on the off chance it becomes useful training data later.
Passive behavioral collection at scale. Modern product analytics tools have made full-funnel behavioral instrumentation accessible to any team. The technical barrier is gone. What remains is the design challenge: instrumentation without intent produces noise, not signal. The volume of collectible data has outpaced most teams' ability to act on it.
Privacy and regulatory pressure. The EU and US regulators have ended the grace period for AI data collection. Public availability of data no longer removes GDPR or CCPA obligations. Web scraping that violates a site's terms is legally exposed in ways it wasn't two years ago. And data provenance — documented chain of custody for any dataset — is increasingly a regulatory requirement, not just a best practice.
The practical implication for product teams: collecting data you have a clear purpose for is now easier to defend than ever. Collecting data you might find useful someday is a growing liability.
Sampling methods: when you can't collect everything
For some signal types and some scale requirements, collecting data from every member of your population isn't feasible. Sampling is how you get valid insight from a subset.
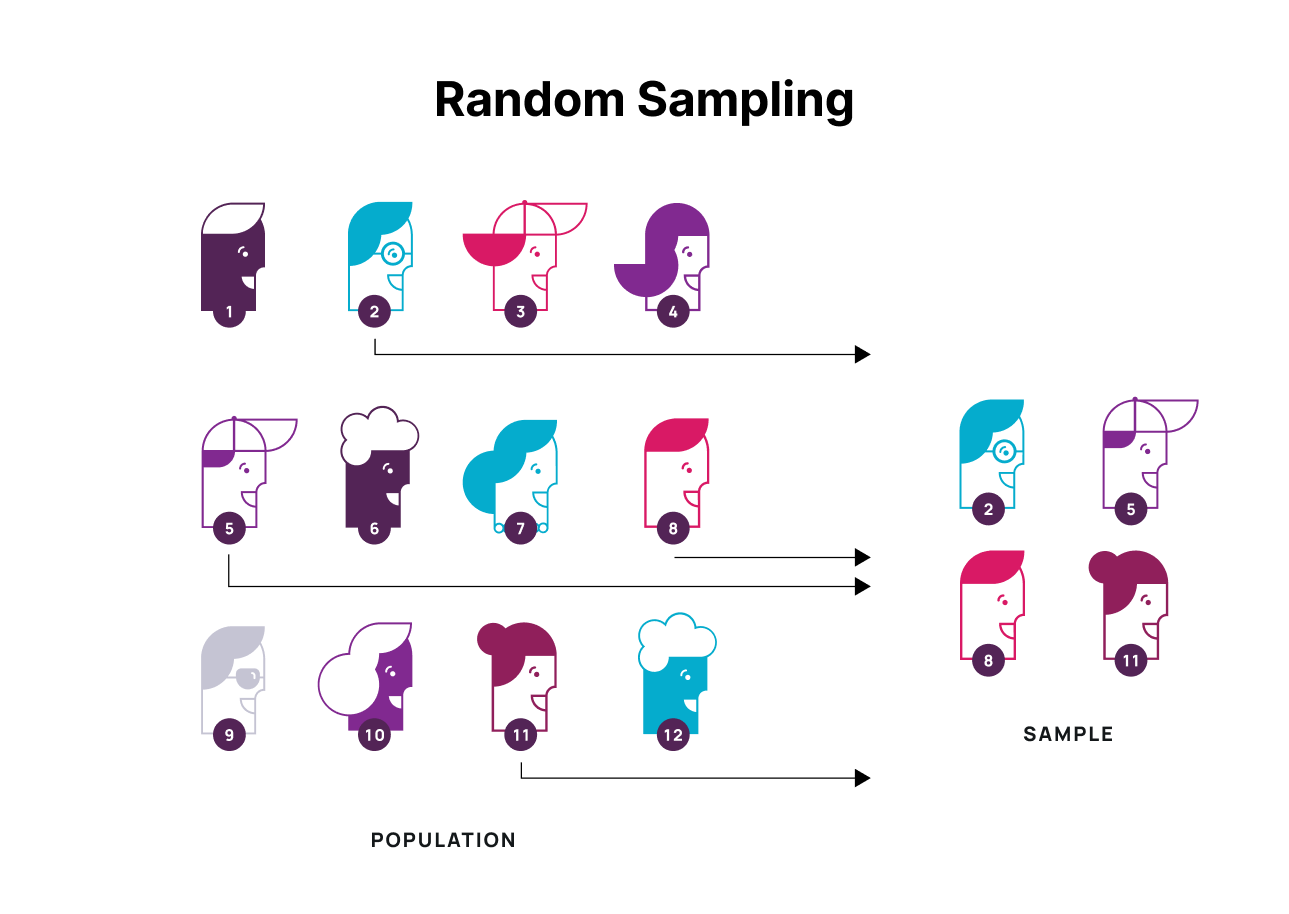
Random sampling selects respondents without a pattern. It's valuable for removing selection bias, but "random" still requires a system — true convenience-based randomness often introduces bias through the selection mechanism itself.
Systematic sampling applies a rule to create regularity — every fifth customer, every tenth transaction. It's orderly but brittle if the ordering itself introduces a pattern. If every fifth user happens to be in a specific cohort, your sample is biased.

Convenience sampling draws from whoever is easiest to reach. It's the least rigorous method and the most commonly used. It's defensible for early-stage hypothesis testing where speed matters more than statistical validity. It's not defensible for product decisions affecting a significant user base.
Clustered sampling works with predefined subgroups — regions, company sizes, user tiers — and collects from the cluster rather than the individual. Useful when the cluster boundaries are meaningful and well-defined. The risk is that a poorly defined cluster produces data that doesn't represent the population you care about.

Stratified sampling divides the population into subgroups by a specific characteristic (age, plan tier, geography), then samples randomly from each subgroup. This is the most rigorous approach when you know your population has meaningful variation along a specific dimension and you need your sample to reflect that variation.
In software products, sampling matters most for A/B test design, ML training dataset construction, and user research recruitment. For real-time operational data, you generally don't sample — you collect every event, because missing events breaks your downstream decision logic.
Step 4: design for sustainability

This step gets skipped most often. It's also the one that produces the most expensive problems.
Sustainability in data collection has four components:
Retention policy. For each signal type, define before you build: how long is this data needed? Operational decisions need recent data, not historical. Behavioral funnels need enough history to detect trends. Compliance records need to match regulatory retention requirements. When you know the answer before you build, you can automate deletion from day one instead of building a cleanup system three years later when storage costs are out of control.
Deletion design. Data you don't have can't be breached and can't create a compliance incident. "Delete after 90 days" is not a privacy policy — it's an engineering decision. Build it into the schema design, not the roadmap.
Cost modeling. Before launching a new collection system, estimate the storage and compute cost at 10x your current scale. If the number is uncomfortable at 10x, it will be uncomfortable before 10x.
Security design. Collection endpoints are an attack surface. Every new type of data you collect is a type of data that can be exposed. This doesn't mean don't collect — it means understand the exposure and design for it from the start. Our SaaS security guide covers the specific patterns that create risk in product data pipelines.
Data collection tools

The market for data collection tools has expanded dramatically. Here's how to map them to your signal requirements.
Survey tools (Jotform, SurveyMonkey, Typeform) — Good for explicit preference and satisfaction signals. Not designed for continuous operational collection.
Product analytics platforms (Mixpanel, Amplitude, PostHog) — Good for behavioral event tracking in digital products. Strong visualization for funnel analysis and cohort comparison.
API integration platforms (Airbyte, Fivetran) — Good for automated data movement between systems. Handles CDC replication, webhook ingestion, schema detection. The infrastructure layer underneath your collection architecture.
Mobile field data tools (GoCanvas, Fulcrum, Forms On Fire) — Good for structured field input in operational contexts: inspections, field service, logistics.
AI-powered extraction tools — Good for processing unstructured documents, emails, and forms into structured data. Rapidly improving category; cost has dropped to near zero for standard document types.
Custom collection layers — The right answer when your signal requirements don't fit a standard tool. Every time we've built a data-intensive product — EveryPig's supply chain transparency platform, HeyPractice's learning performance engine, Revenue Boosters' route optimization SaaS — the collection architecture was purpose-built. Not because off-the-shelf tools are bad, but because the signal requirements were specific enough that a generic tool would have captured the wrong thing or at the wrong granularity.
The build-vs-buy question for data collection is the same as for any software component: use a standard tool for standard signals, and build custom for the signals where your competitive advantage lives. Our data management platform guide covers how to think about this decision for data infrastructure broadly.
The full picture
Every guide on this topic covers the same 6 methods. Most of them are right about what the methods are. None of them address the sequence.
The Intent-First Collection Model:
- Define the decision the data needs to drive
- Map the signal that indicates something decision-relevant happened
- Choose the method that captures that signal at the right frequency and cost
- Design the retention, deletion, and security policy before you build
Teams that follow this sequence build data systems that get used. Teams that skip to step 3 build data systems that generate storage bills.
If you're designing a data collection layer for a product from scratch, or you've inherited one that's grown past what you can usefully act on, the first question to answer isn't "which method?" It's "what decision?"
If you want to talk through how this applies to a specific product — or see how Brocoders has architected data collection for products across agritech, healthtech, field operations, and edtech — our product development team works through this as part of every discovery engagement. And if you're adding AI or ML capabilities to an existing product, our AI development practice starts with the signal architecture, not the model selection.
Our product development expertise also extends to comprehensive SaaS solutions, helping teams build scalable data systems that drive real business value. Discover how the Brocoders team delivers effective SaaS development tailored to your needs.
Related reading: Data management platforms | Data lake vs. data warehouse | Zero-party data
FAQ
The core methods are surveys, interviews, behavioral observation (passive tracking), API-based automated collection, structured forms, and secondary data analysis. In 2026, AI-powered extraction and synthetic data generation have added two more for teams building ML products. The right method depends on what signal you need and what decision it supports — not on the data type alone.
There isn't one. Behavioral event tracking is the default for most product analytics use cases because it's continuous and passive. But the right answer depends on the specific signal your product decision requires. A learning platform needs session performance data. A field operations app needs structured input from field workers. A supply chain product needs event streams from integrated systems. The method follows from the signal requirement.
Qualitative data is descriptive — it captures opinions, context, and reasoning. It tells you why. Quantitative data is numeric — it captures counts, rates, and measurements. It tells you how many and how often. Most product decisions need both: quantitative data to identify the pattern, qualitative data to understand what's driving it.
Primary data is collected directly for your specific purpose — surveys you run, events your product tracks, interviews you conduct. Secondary data is collected by someone else for a different purpose — industry reports, public datasets, published research. Primary data is more expensive but more precisely matched to your question. Secondary data is faster and cheaper, and it's most useful for establishing context before you invest in a primary collection system.
Start with the decision the data needs to drive, not the data type. Then identify the specific signal that tells you something decision-relevant happened. Then — and only then — evaluate which method captures that signal reliably at your required frequency and cost. This sequence prevents the most common data collection failure: building pipelines that generate data nobody acts on.
Collecting without a defined decision to drive. Treating "we'll analyze it later" as a reason to store data. Skipping retention policy design until storage costs force it. Using survey data as a proxy for behavioral data when behavioral data is available and more accurate. Building collection instrumentation before mapping what signal is actually needed.
AI has made automated extraction from documents and forms near-zero cost, made synthetic data generation viable as a training data source (reducing the need to store raw behavioral data indefinitely), and enabled passive behavioral tracking at a scale no manual method could match. It's also increased regulatory pressure: data provenance requirements and GDPR/CCPA enforcement have made "collect everything" a harder position to defend than it was even two years ago.
Research data collection is structured, time-bound, and designed for a specific study. It ends. Product data collection is continuous, operational, and embedded in your software. It scales with your user base and runs indefinitely. The methods overlap, but the architecture decisions don't. Most data collection guides are written for the research context. If you're building software, apply the intent-first sequence described here rather than a research methodology framework.